[md]**【Pandas】深入解析pandas中的统计汇总函数`argmin()`** 在数据分析的过程中,经常需要找出数据集中某个指标的最小值,以及该最小值在数据中的位置。Pandas,作为Python数据分析的利器,提供了许多用于此类任务的函数。其中,`argmin()` 函数就是用来找...
[md]  在数据处理和分析的世界中,`pandas` 是一个强大的工具,它提供了许多用于数据清洗、转换和统计分析的函数。其中,`aggregate()`(或简称 `agg()`)函数是 `pandas` 中一个...
[md]**Python字典由值(Value)查找键(Key)的方法介绍** 在Python中,字典(Dictionary)是一种非常有用的数据结构,它允许我们存储键值对(key-value pairs)。然而,与列表(List)或元组(Tuple)不同,字典并不直接支持通过值来查找键。这是因为字典的...
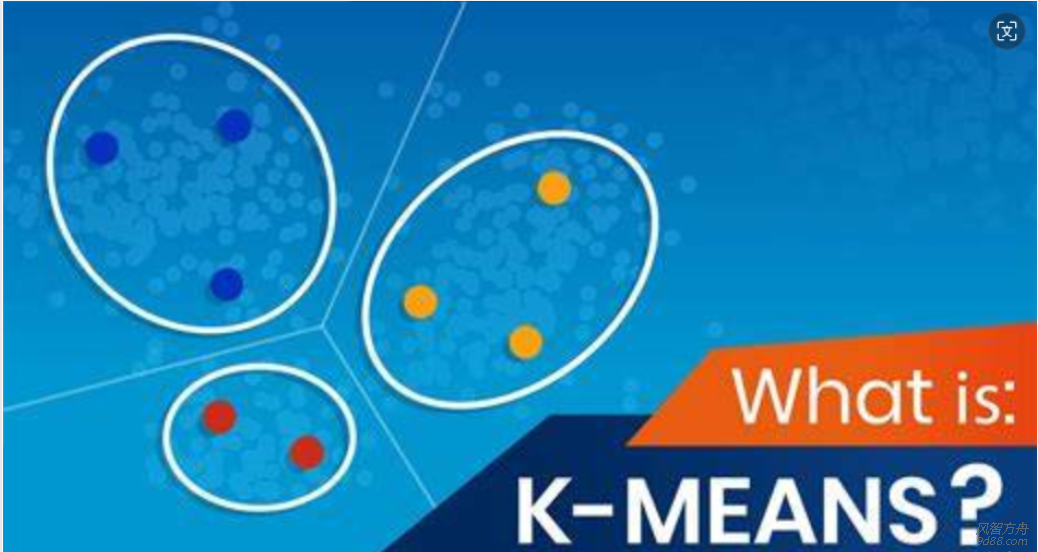
[md] 在数据分析中,我们经常需要对数据进行分组并计算每个组的统计信息。Pandas库中的`groupby()`函数提供了强大的数据分组功能,它允许我们根据一个或多个列的值将数据分成多个...
[md] 在数据分析与预测领域,时间序列分析是一个非常重要的工具,用于捕捉随时间变化的模式和趋势。时间序列预测模型在多个领域都有广泛应用,如金融、气候、交通流量等。本文将介绍7种常见的时间序列预测模型,并提供相应的Python代码示例,同时解释选择这...
[md] 在Python编程中,我们经常需要将数据(如列表、字典等)保存到本地文件,以便后续读取、分析或与其他系统交换数据。Python提供了多种格式来保存这些数据,包括文本文件(txt)、JSON文件和pickle文件。每种格式都有其独特的用途和优势。本文将详细介绍...
[md]  在数据分析中,了解变量之间的相关性是一个至关重要的步骤。Pandas库中的`corr()`函数为我们提供了计算DataFrame中不同列之间相关性系数的功能,特别是皮尔逊相关系数(Pe...
[md] 在数据分析和处理中,我们经常需要了解数据的分布情况,尤其是数据的分位数。Pandas库中的`quantile()`函数为我们提供了这一功能,使得我们可以轻松地计算数据集的任意分位数。本文将深入解析Pandas中的`quantile()`函数,包括其使用方法、原因和可能遇...
[md] 在数据分析和处理中,了解变量之间的相关性是非常重要的。Pandas库中的`cov()`函数为我们提供了计算数据集中变量之间协方差的功能,这对于分析变量间的线性关系至关重要。本...
[md]#### Step1.本地安装doccano(本地测试环境python=3.8) - 先创建一个python3.8版本的虚拟环境,conda create -n doccano python==3.8 ;activate doccano - 再$ pip install doccano #### Step2.初始化数据库和账户(用户名和密码可替换成自定义的值) ...