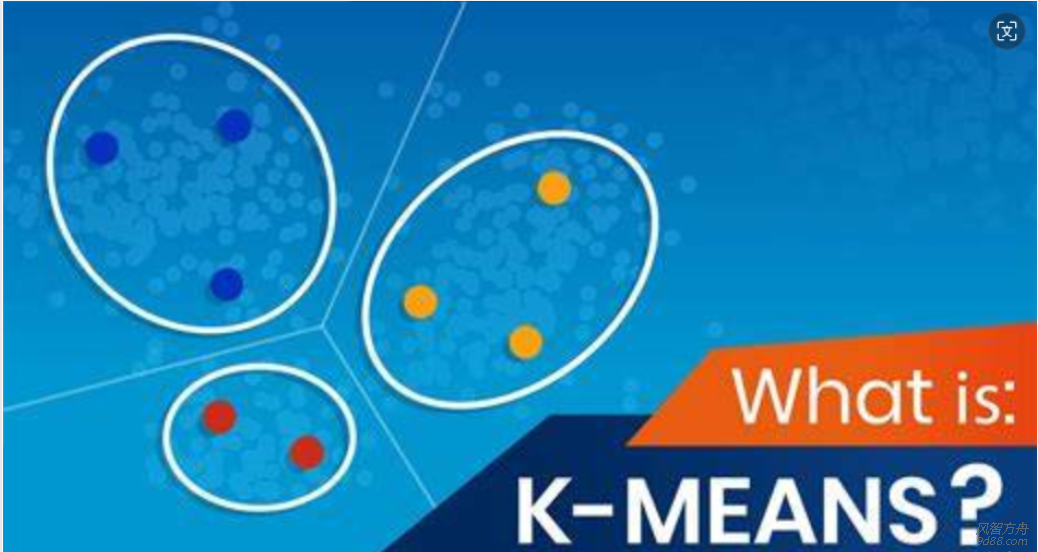
[md] ### 一、引言 ##### 1、简述聚类分析的重要性及其在机器学习中的应用 聚类分析,作为机器学习领域中的一种无监督学习方法,在数据探索与知识发现过程中扮演着举足轻重的角色。它能够在没有先验知识或标签信息的情况下,通过挖掘数据中的内...
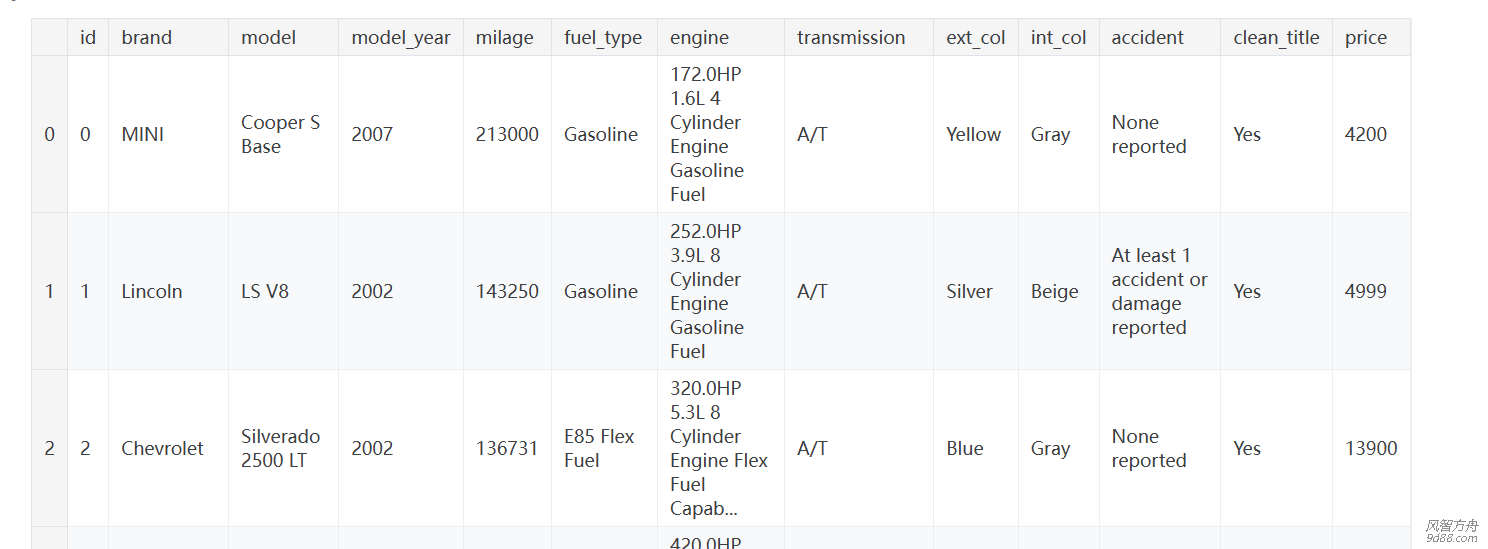
[md]### 一、项目分析 1.1 项目任务 kaggle二手车价格回归预测项目,目的**根据各种属性预测二手车的价格**。 1.2 评估准则 评估的标准是均方根误差: 1.3 ...
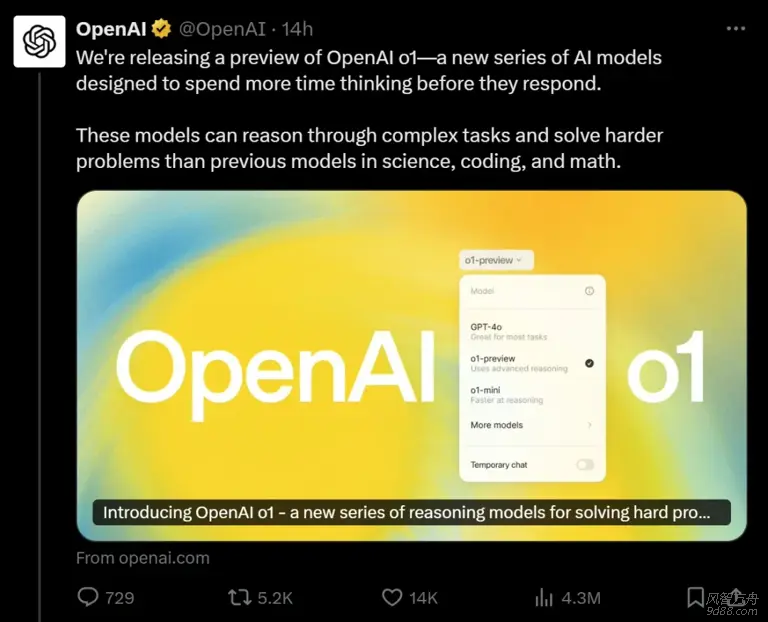
[md]在毫无预兆之下,OpenAI 昨日震撼发布了其全新模型o1,标志着一系列专注于“推理”能力模型系列的启航。据OpenAI官方介绍,o1与先前广受赞誉的GPT-4o相比,显著的特点在于其更加深思熟虑的响应方式,即在给出答案前会投入更多时间进行深度思考与分析。这...
[md]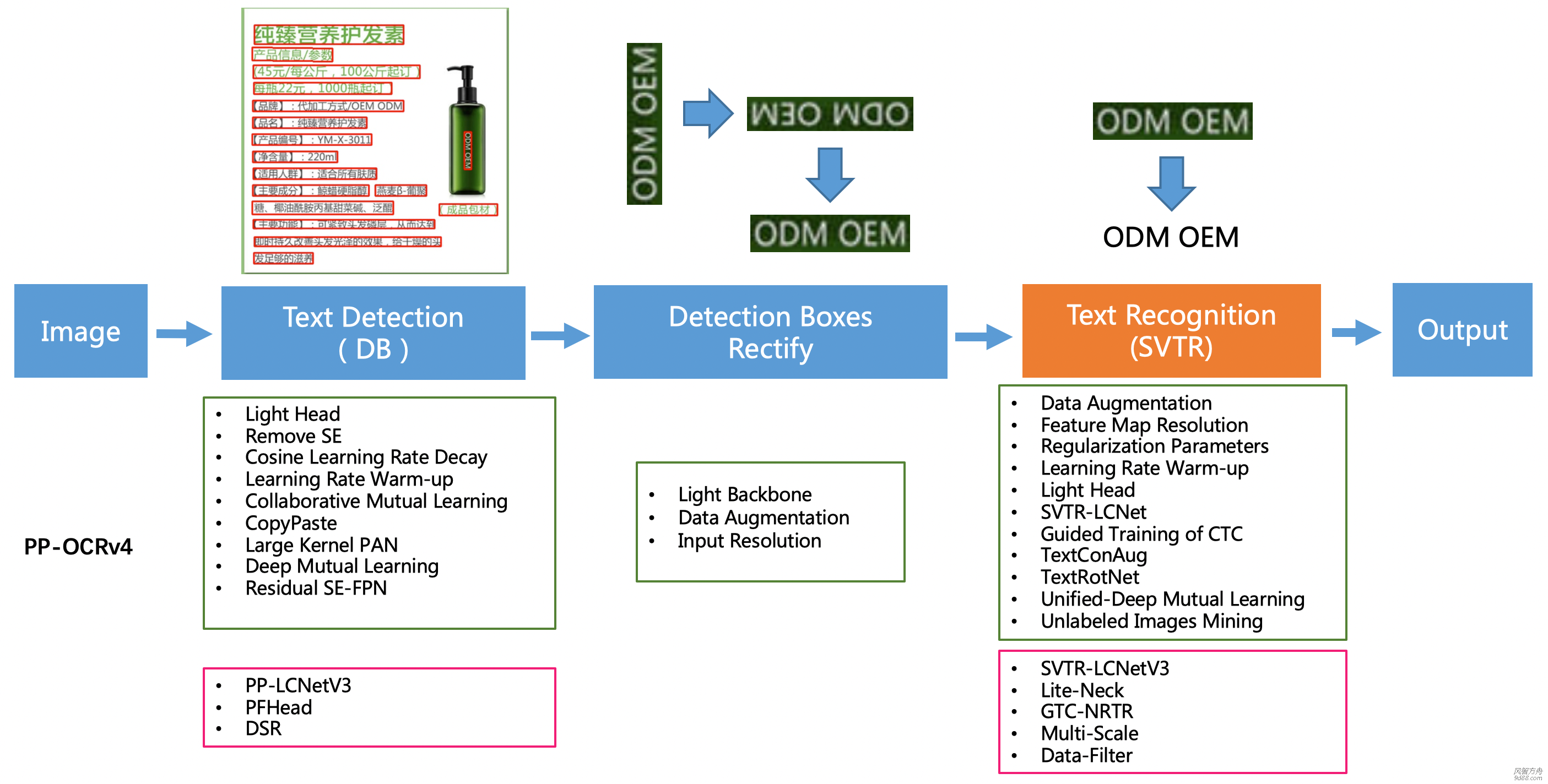 ### 1、使用默认路径 ``` import cv2 from paddleocr import PaddleOCR paddleocr = PaddleOCR(lang='ch', show_log=False) img = cv2.imread('test.jpg') ...
[md]1.安装与运行 准备: 安装conda 创建虚拟环境conda create -n google_ocr python=3.9 激活虚拟环境 conda activate google_ocr 1.1 安装PaddlePaddle pip install --upgrade pip # 如果您的机器安装的是CUDA9或CUDA10,请运行以下命令安装 python -m p...
[md]### 1. 文本识别模型微调 #### 1.1 数据选择 数据量:不更换字典的情况下,建议至少准备5000张的文本识别数据集用于模型微调;如果更换了字典(不建议),需要的数量更多。 数据分布:建议分布与实测场景尽量一致。如果实测场景包含大量短文本,则训练...
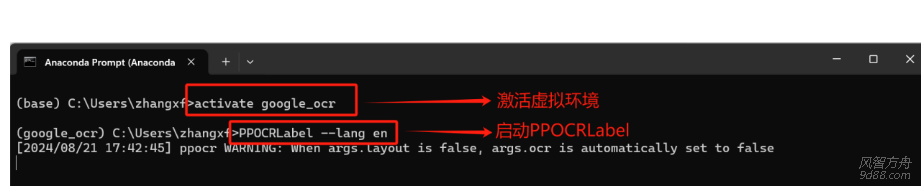
[md]> 本帖最后由 云天徽上 于 2024-8-20 14:20 编辑 > 本帖最后由 云天徽上 于 2024-8-19 17:20 编辑 ### 1、获取微调检测模型的数据 检测模型的数据集的制作和获取具体参考PPOCRLabel进行数据标注,并划分检测数据集的步骤;得到的检测结果如下图所...
[md]# 运行环境准备 Windows和Mac用户推荐使用Anaconda搭建Python环境,Linux用户建议使用docker搭建Python环境。 推荐环境: PaddlePaddle >= 2.1.2 Python 3.7 CUDA10.1 / CUDA10.2 CUDNN 7.6 如果您已经安装Python环境,可以直接参考PaddleOCR快速开...
[md] # 【向量库】FAISS向量库的介绍和基本使用(增删改查) 在数据科学和机器学习领域,处理大规模高维向量数据是一项常见且挑战性的任务。为了高效地存储、检索和管理这些向量...
[md] Pinecone是一个实时、高性能的向量数据库,专为大规模向量集的高效索引和检索而设计。它提供亚秒级的查询响应时间,确保用户可以迅速获取所需信息。Pinecone采用高度可伸缩...